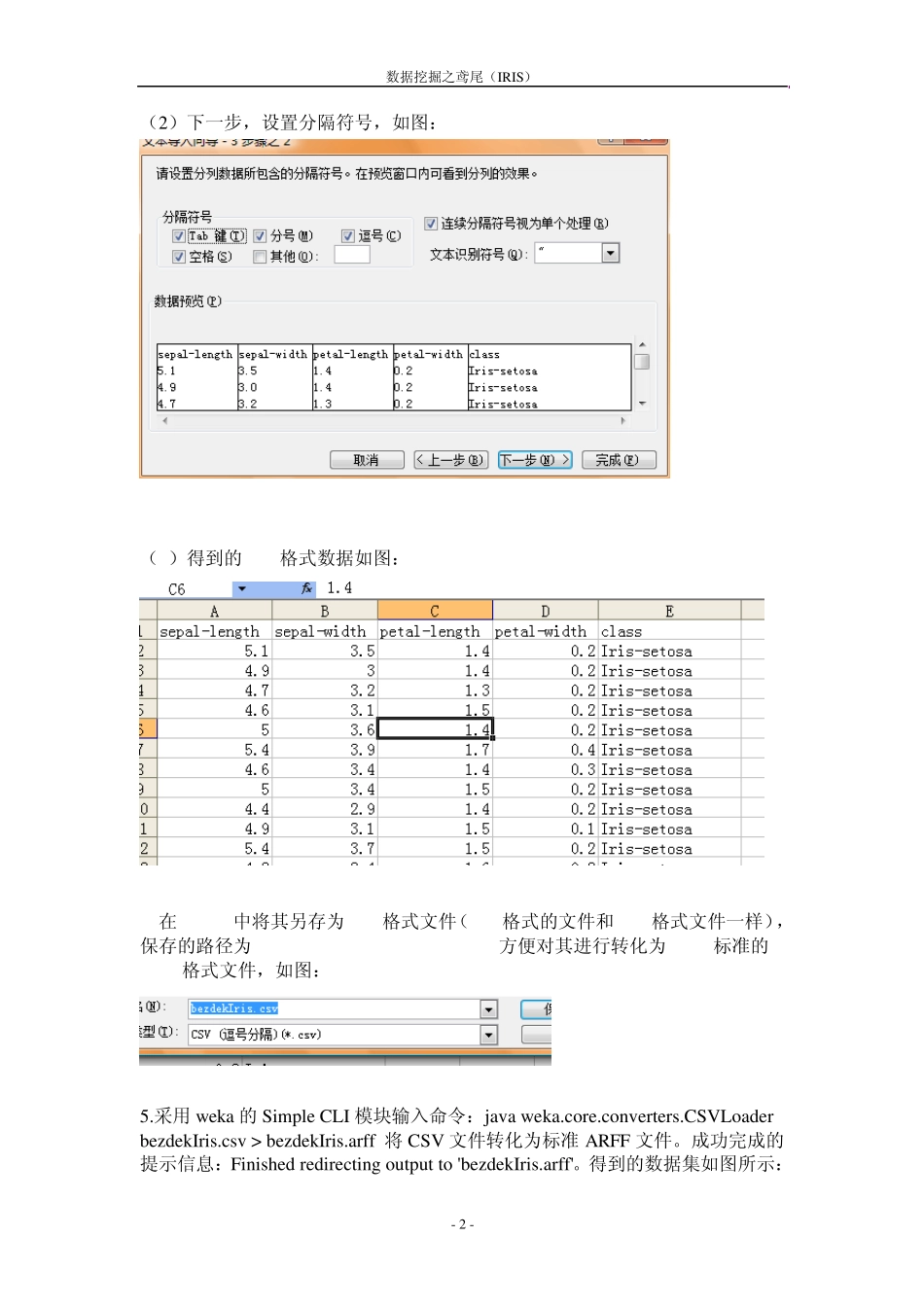
数据挖掘之鸢尾(IRIS) - 1 - 第一部分 概述 1.数据挖掘目的:根据已有的数据信息,寻找出鸢尾的属性之间存在怎样的关联规则。 2.数据源:UCI 提供的150 个实例,每个实例有5 个属性。 3.数据集的属性信息: (1). sepal length in cm 萼片长度(单位:厘米)(数值型) (2). sepal width in cm 萼片宽度(单位:厘米)(数值型) (3). petal length in cm 花瓣长度(单位:厘米)(数值型) (4). petal width in cm 花瓣宽度(单位:厘米)(数值型) (5). class: 类型(分类型),取值如下 -- Iris Setosa 山鸢尾 -- Iris Versicolor 变色鸢尾 -- Iris Virginica 维吉尼亚鸢尾 4.试验中我们采用 bezdekIris.data 数据集,对比 UCI 发布的iris.data 数据集(08-Mar-1993)和 bezdekIris.data 数据集(14-Dec-1999),可知前者的第35 个实例 4.9,3.1,1.5,0.1,Iris-setosa 和第38 个实例 4.9,3.1,1.5,0.1,Iris-setosa,后者相应的修改为:4.9,3.1,1.5,0.2,Iris-setosa 和 4.9,3.1,1.4,0.1,Iris-setosa。 第二部分 将 U CI 提供的数据转化为标准的AR FF 数据集 1. 将数据集处理为标准的数据集,对于原始数据,我们将其拷贝保存到 TXT 文档,采用 UltraEdit 工具打开,为其添加属性信息。如图: 2.(1)将 bezdekIris.txt 文件导入 Microsoft Office Excel(导入时,文本类型选择文本文件),如图: 数据挖掘之鸢尾(IRIS) - 2 - (2)下一步,设置分隔符号,如图: (3)得到的XLS格式数据如图: 4.在Excel中将其另存为CSV格式文件(CSV格式的文件和XLS格式文件一样),保存的路径为C:\Program Files\Weka-3-6,方便对其进行转化为weka标准的arff格式文件,如图: 5.采用weka 的Simple CLI 模块输入命令:java weka.core.converters.CSVLoader bezdekIris.csv > bezdekIris.arff 将CSV 文件转化为标准ARFF 文件。成功完成的提示信息:Finished redirecting output to 'bezdekIris.arff'。得到的数据集如图所示: 数据挖掘之鸢尾(IRIS) - 3 - 6. 至此得到了标准的ARFF 格式文件。 第三部分 采用关联规则对 ARFF 数据集进行处理 1. 对 ARFF 数据集进行预处理,即进行数据的离散化,将 sepal-length, sepal-width, petal-length 和 petal-width 四个数值型的数据转化为分类型的数据,设置相应的参数为:weka.filte...







 VIP
VIP

