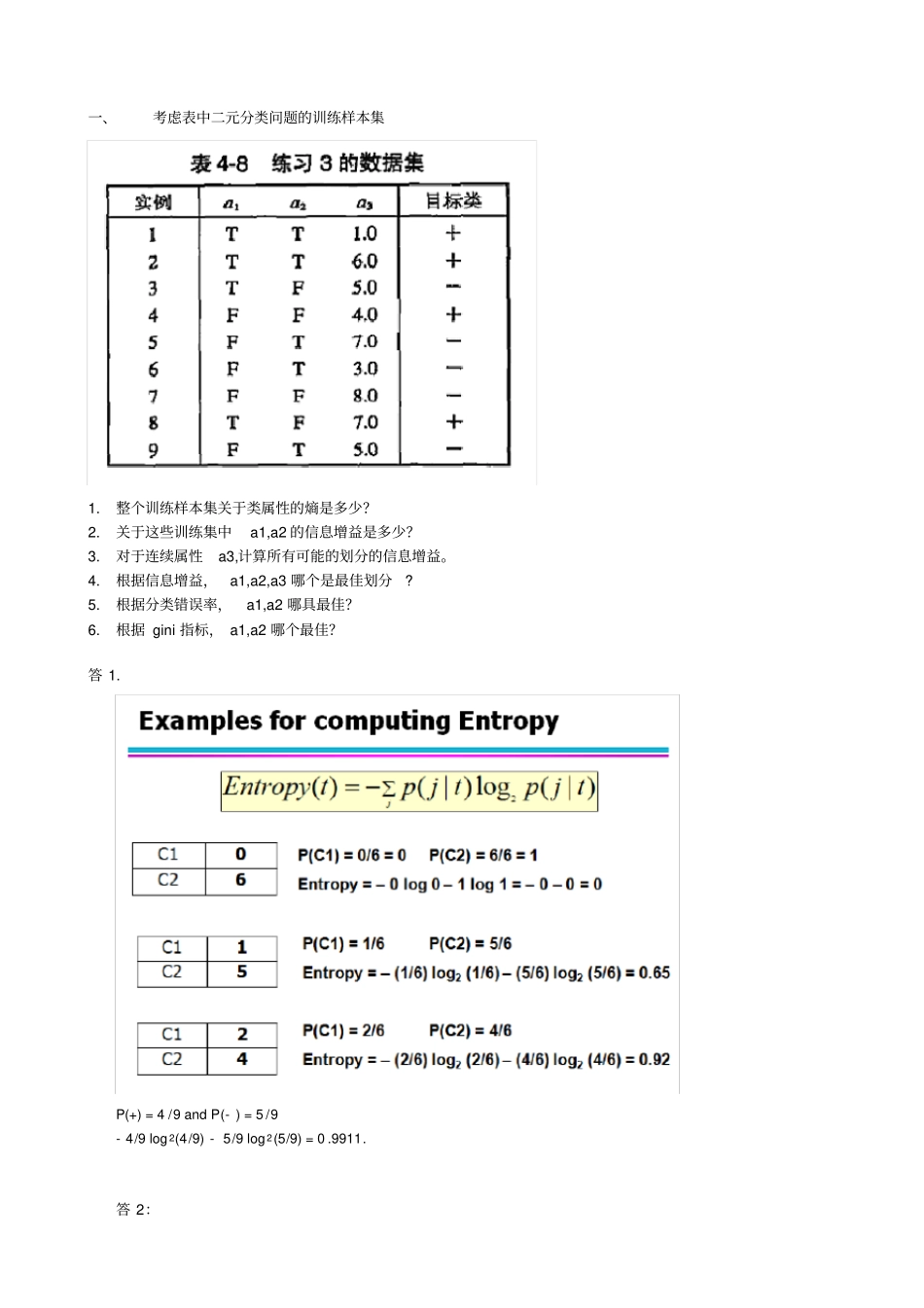
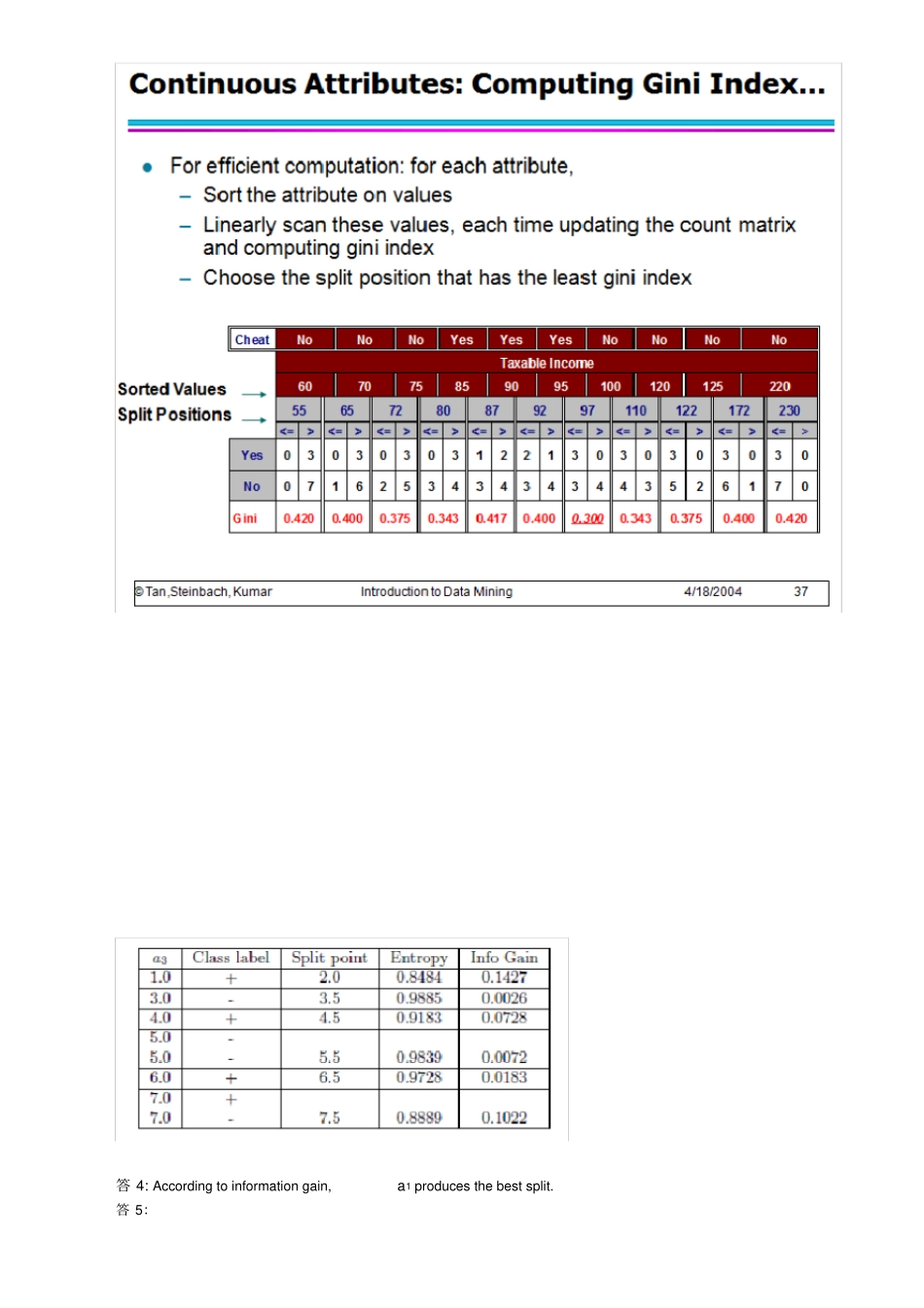
一、考虑表中二元分类问题的训练样本集1.整个训练样本集关于类属性的熵是多少?2.关于这些训练集中a1,a2的信息增益是多少?3.对于连续属性a3,计算所有可能的划分的信息增益。4.根据信息增益,a1,a2,a3哪个是最佳划分?5.根据分类错误率,a1,a2哪具最佳?6.根据gini指标,a1,a2哪个最佳?答1.P(+)=4/9andP(-)=5/9-4/9log2(4/9)-5/9log2(5/9)=0.9911.答2:(估计不考)答3:答4:Accordingtoinformationgain,a1producesthebestsplit.答5:Forattributea1:errorrate=2/9.Forattributea2:errorrate=4/9.Therefore,accordingtoerrorrate,a1producesthebestsplit.答6:二、考虑如下二元分类问题的数据集1.计算a.b信息增益,决策树归纳算法会选用哪个属性2.计算a.bgini指标,决策树归纳会用哪个属性?这个答案没问题3.从图4-13可以看出熵和gini指标在[0,0.5]都是单调递增,而[0.5,1]之间单调递减。有没有可能信息增益和gini指标增益支持不同的属性?解释你的理由Yes,eventhoughthesemeasureshavesimilarrangeandmonotonousbehavior,theirrespectivegains,Δ,whicharescaleddifferencesofthemeasures,donotnecessarilybehaveinthesameway,asillustratedbytheresultsinparts(a)and(b).贝叶斯分类1.P(A=1|-)=2/5=0.4,P(B=1|-)=2/5=0.4,P(C=1|-)=1,P(A=0|-)=3/5=0.6,P(B=0|-)=3/5=0.6,P(C=0|-)=0;P(A=1|+)=3/5=0.6,P(B=1|+)=1/5=0.2,P(C=1|+)=2/5=0.4,P(A=0|+)=2/5=0.4,P(B=0|+)=4/5=0.8,P(C=0|+)=3/5=0.6.2.3.P(A=0|+)=(2+2)/(5+4)=4/9,P(A=0|-)=(3+2)/(5+4)=5/9,P(B=1|+)=(1+2)/(5+4)=3/9,P(B=1|-)=(2+2)/(5+4)=4/9,P(C=0|+)=(3+2)/(5+4)=5/9,P(C=0|-)=(0+2)/(5+4)=2/9.4.LetP(A=0,B=1,C=0)=K5.当的条件概率之一是零,则估计为使用m-估计概率的方法的条件概率是更好的,因为我们不希望整个表达式变为零。1.P(A=1|+)=0.6,P(B=1|+)=0.4,P(C=1|+)=0.8,P(A=1|-)=0.4,P(B=1|-)=0.4,andP(C=1|-)=0.22.LetR:(A=1,B=1,C=1)bethetestrecord.Todetermineitsclass,weneedtocomputeP(+|R)andP(-|R).UsingBayestheorem,P(+|R)=P(R|+)P(+)/P(R)andP(-|R)=P(R|-)P(-)/P(R).SinceP(+)=P(-)=0.5andP(R)isconstant,RcanbeclassifiedbycomparingP(+|R)andP(-|R).Forthisquestion,P(R|+)=P(A=1|+)×P(B=1|+)×P(C=1|+)=0.192P(R|-)=P(A=1|-)×P(B=1|-)×P(C=1|-)=0.032SinceP(R|+)islarger,therecordisassignedto(+)class.3.P(A=1)=0.5,P(B=1)=0.4andP(A=1,B=1)=P(A)×P(B)=0.2.Therefore,AandBareindependent.4.P(A=1)=0.5,P(B=0)=0.6,andP(A=1,B=0)=P(A=1)×P(B=0)=0.3.AandBarestillindependent.5.CompareP(A=1,B=1|+)=0.2againstP(A=1|+)=0.6andP(B=1|Class=+)=0.4.SincetheproductbetweenP(A=1|+)andP(A=1|-)arenotthesameasP(A=1,B=1|+),AandBarenotconditionallyindependentgiventheclass.三、使用下表中的相似度矩阵进行单链和全链层次聚类。绘制树状况显示结果,树状图应该清楚地显示合并的次序。Therearenoapparentrelationshipsbetweens1,s2,c1,andc2.A2:Percentageoffrequentitemsets=16/32=50.0%(includingthenullset).A4:FalsealarmrateistheratioofItothetotalnumberofitemsets.SincethecountofI=5,thereforethefalsealarmrateis5/32=15.6%.