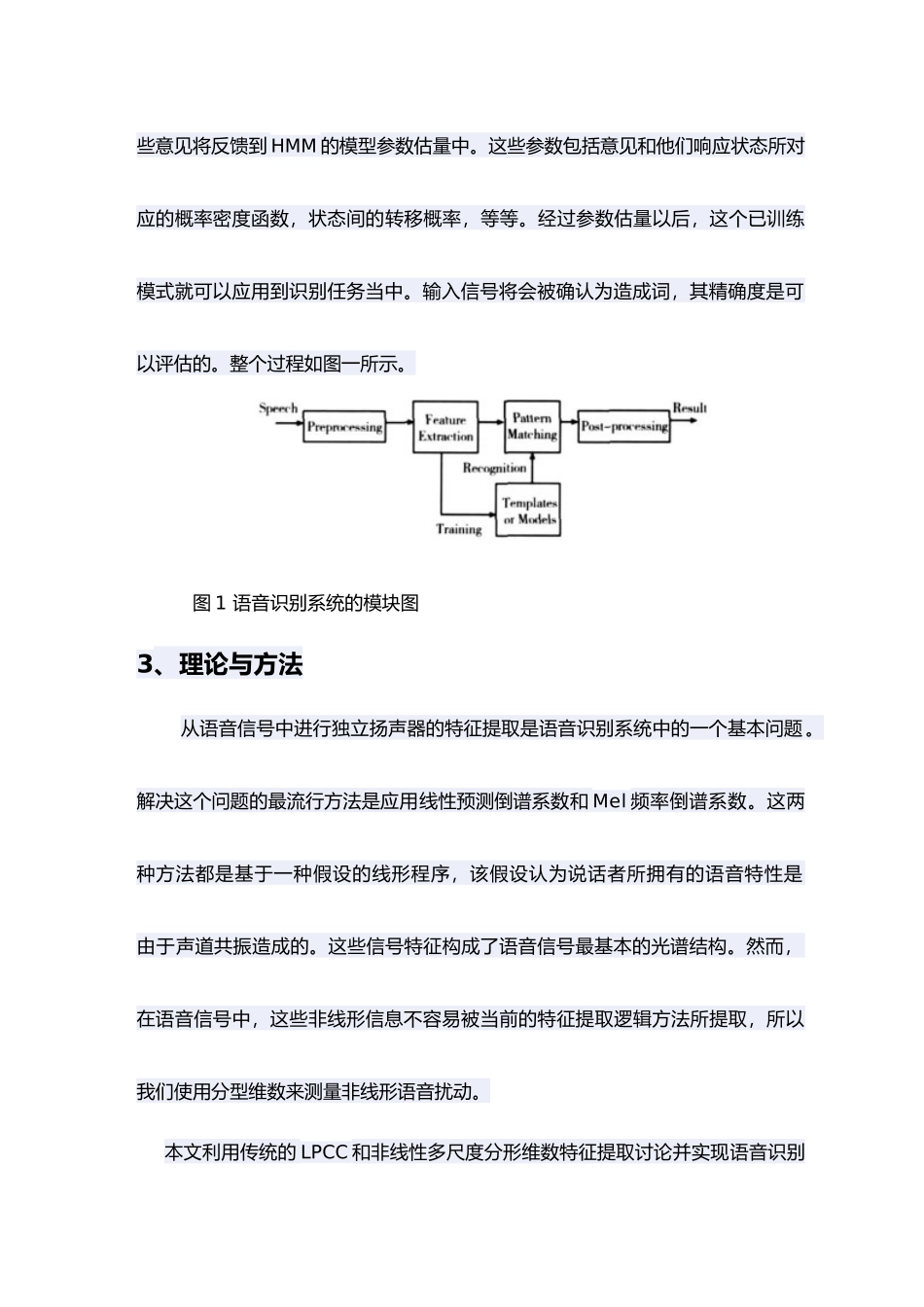
毕业设计(论文)外文资料翻译学 院: 自动化工程学院 专 业:□自动化□测控技术与仪器外文出处:附 件: 1. 外文资料翻译译文; 2. 外文原文。 附件 1:外文资料翻译译文改进型智能机器人的语音识别方法2、语音识别概述最近,由于其重大的理论意义和有用价值,语音识别已经受到越来越多的关(用外文写)注。到现在为止,多数的语音识别是基于传统的线性系统理论,例如隐马尔可夫模型和动态时间规整技术。随着语音识别的深度讨论,讨论者发现,语音信号是一个复杂的非线性过程,假如语音识别讨论想要获得突破,那么就必须引进非线性系统理论方法。最近,随着非线性系统理论的进展,如人工神经网络,混沌与分形,可能应用这些理论到语音识别中。因此,本文的讨论是在神经网络和混沌与分形理论的基础上介绍了语音识别的过程。 语音识别可以划分为独立发声式和非独立发声式两种。非独立发声式是指发音模式是由单个人来进行训练,其对训练人命令的识别速度很快,但它对与其他人的指令识别速度很慢,或者不能识别。独立发声式是指其发音模式是由不同年龄,不同性别,不同地域的人来进行训练,它能识别一个群体的指令。一般地,由于用户不需要操作训练,独立发声式系统得到了更广泛的应用。 所以,在独立发声式系统中,从语音信号中提取语音特征是语音识别系统的一个基本问题。语音识别包括训练和识别,我们可以把它看做一种模式化的识别任务。通常地,语音信号可以看作为一段通过隐马尔可夫模型来表征的时间序列。通过这些特征提取,语音信号被转化为特征向量并把它作为一种意见,在训练程序中,这些意见将反馈到 HMM 的模型参数估量中。这些参数包括意见和他们响应状态所对应的概率密度函数,状态间的转移概率,等等。经过参数估量以后,这个已训练模式就可以应用到识别任务当中。输入信号将会被确认为造成词,其精确度是可以评估的。整个过程如图一所示。 图 1 语音识别系统的模块图3、理论与方法从语音信号中进行独立扬声器的特征提取是语音识别系统中的一个基本问题。解决这个问题的最流行方法是应用线性预测倒谱系数和 Mel 频率倒谱系数。这两种方法都是基于一种假设的线形程序,该假设认为说话者所拥有的语音特性是由于声道共振造成的。这些信号特征构成了语音信号最基本的光谱结构。然而,在语音信号中,这些非线形信息不容易被当前的特征提取逻辑方法所提取,所以我们使用分型维数来测量非线形语音扰动。本文利用传统的 LPCC...