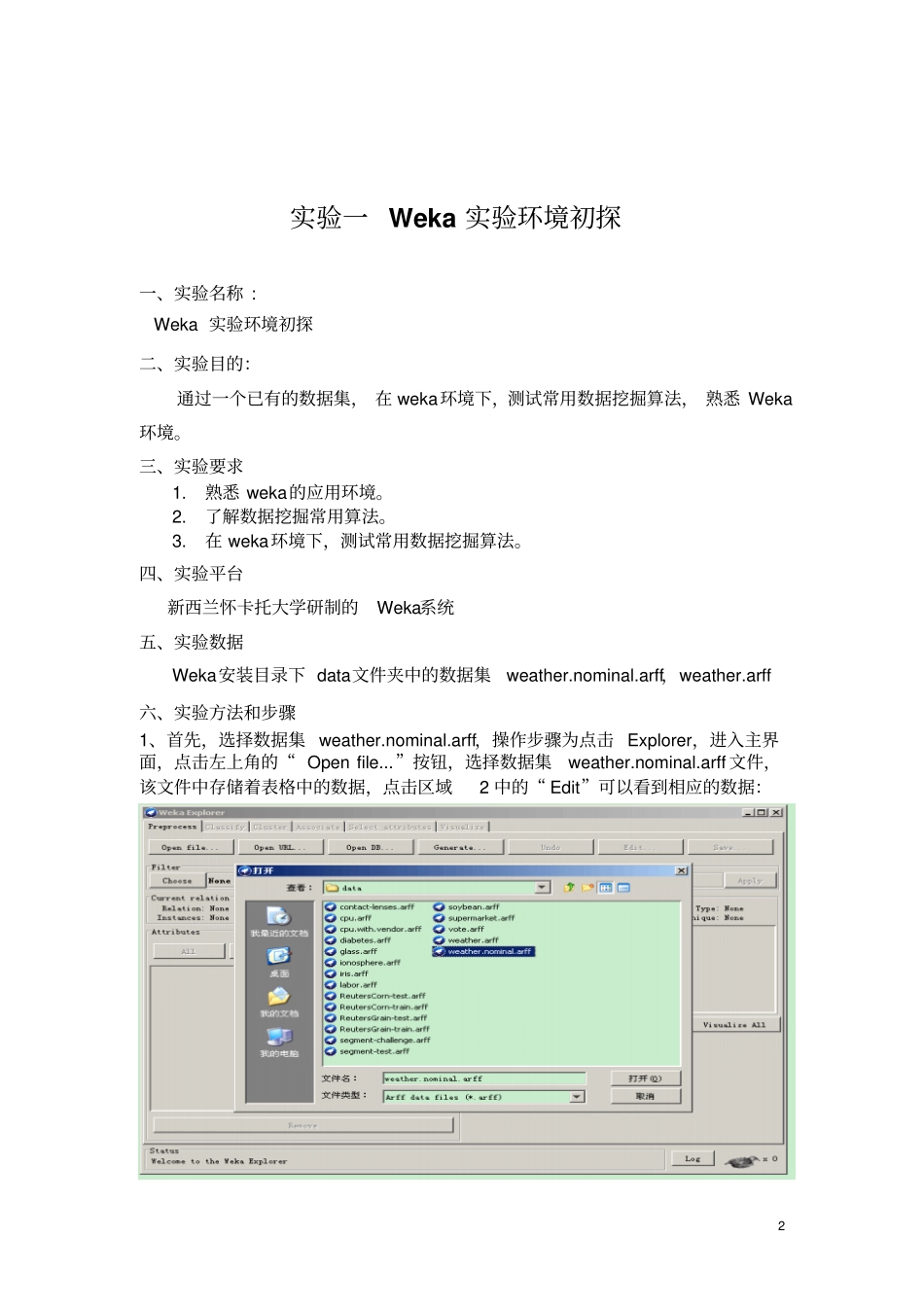
1 数据仓库与数据挖掘实验指导书东北石油大学计算机与信息技术系王浩畅2 实验一 Weka 实验环境初探一、实验名称 : Weka 实验环境初探二、实验目的:通过一个已有的数据集, 在 weka环境下,测试常用数据挖掘算法, 熟悉 Weka环境。三、实验要求1.熟悉 weka的应用环境。2.了解数据挖掘常用算法。3.在 weka环境下,测试常用数据挖掘算法。四、实验平台新西兰怀卡托大学研制的Weka系统五、实验数据Weka安装目录下 data文件夹中的数据集weather.nominal.arff,weather.arff六、实验方法和步骤1、首先,选择数据集 weather.nominal.arff,操作步骤为点击 Explorer,进入主界面,点击左上角的“ Open file...”按钮,选择数据集weather.nominal.arff 文件,该文件中存储着表格中的数据,点击区域2 中的“ Edit”可以看到相应的数据:3 选择上端的Associate 选项页,即数据挖掘中的关联规则挖掘选项,此处要做的是从上述数据集中寻找关联规则。点击后进入如下界面:2、现在打开 weather.arff,数据集中的类别换成数字。4 选择上端的 Associate选项页,但是在 Associate选项卡中 Start按钮为灰色的,也就是说这个时候无法使用Apriori 算法进行规则的挖掘, 原因在于 Apriori 算法不能应用于连续型的数值类型。 所以现在需要对数值进行离散化,就是类似于将20-30℃划分为“热”,0-10℃定义为“冷”,这样经过对数值型属性的离散化,就可以应用 Apriori 算法了。 Weka 提供了良好的数据预处理方法。第一步:选择要预处理的属性temperrature5 从中可以看出,对于“温度”这一项,一共有12 条不同的内容,最小值为64(单位:华氏摄氏度,下同) ,最大值为 85,选择过滤器“ choose”按钮,或者 在 同 行 的 空 白 处 点 击 一 下 , 即 可 弹 出 过 滤 器 选 择 框 , 逐 级 找 到“Weka.filters.unsupervised.attribute.Discretize”,点击;若无法关闭这个树,在树之外的地方点击“Explorer ”面板即可。现在“ Choose ”旁边的文本框应该显示“Discretize -B 10 -M -0.1 -R first-last ”。点击这个文本框会弹出新窗口以修改离散化的参数。因为这里不打算对所有的属性离散化,只是针对对第 2 个和第 3 个属性,故把 attributeIndices 右边改成 “2,3”。计划把这两个属性都分成3 段,于是把“bins”改成“3”。其它文本框里的值不用更改,关于这些参数的意义可以...







 VIP
VIP
